I may be highly influenced by having worked with APIs for so long. This week I’ve been debugging a cloud pub/sub system. Specifically, two topics with one publisher and four subscriber services each.
The problem was data being corrupted intermittently at some point of the many subscribers (or the publisher? 🤔). And by corruption I mean that the persistence and data integrity were not reliable, thus, incorrect (or no) values were being persisted.
I already dislike being at the debugging phase; not because I dislike debugging -I find it enjoyable-, but because I wish this problem was found during earlier phases. And adding the thicc abstraction layer pub/sub systems have was extra unpleasant.
Publishing-subscribe systems are expected to be asynchronous and idempotent, with failure in mind (as everything?), so data traceability is difficult if you’re only storing your transformed data.
Look at this diagram:
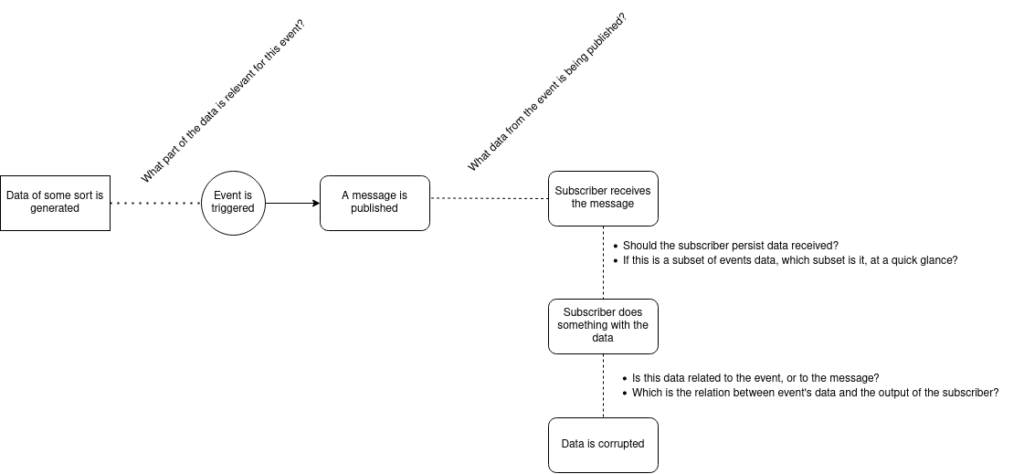
Valid questions to make. Publisher/subscriber data flow pattern standards should tackle a couple of them, but I think not all of them. Of course editing event data is not recommended (why not do it at the edge?), but what about the input of the subscriber? Should be persisted? or are we expecting to trace it through message/ack ids? Doable, but cumbersome.
Patterns and implementations can be discussed over an over, but every time I need to work with pub/sub messaging system I stress over data traceability. I’m always looking for a third system that does this, and then I’m back thinking that pub/sub should be as much data agnostic as it can, and the traceability of the data should be done by proper persistence. Another way may be to use a centralized logging per event.
I’m leaning towards creating some sort of container where I run the event generation, message publishing, the subscriber and the data transformation in the same runtime. Wish me luck.